收藏篇:SQL优化的36个建议!干货满满!
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
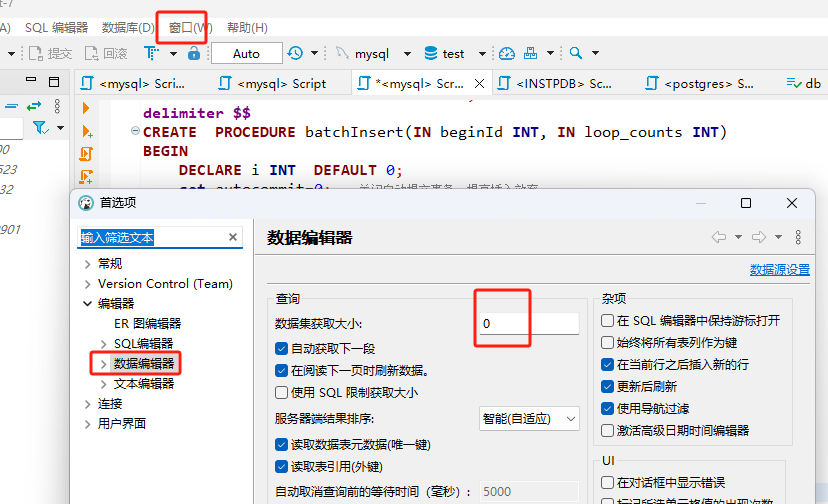
一、优化知识储备1、mysql优化原则:尽量避免全表扫描、合理使用索引、避免返回大量数据给客户端、避免使用游标、避免频繁创建删除临时表。 联表查询时尽量用小表驱动大表,小的数据集驱动大的数据集,小表放左边。 2、学会查看SQL执行计划 explain select * from users; 速度排行: type: system > const > eq_ref > ref > range > index > ALL ---------------------------------------- ALL 全表扫描 index 扫描索引上全部数据,比ALL快一点 场景:count(*) range 范围 user_id>200 ref 普通非唯一索引 user_name=100 eq_ref 唯一索引 const 唯一索引且条件是普通常量 user_id=100 system 系统表 3、SQL优化目标:优化到range及以上级别,index也很慢和ALL基本一样。 4、注意客户端自带的limit会影响你的判断。(干货啊!!!这个一般百度上是没有的,百度不到!!但是却容易被忽视!!!) 客户端一般都有默认带上limit 200,比如dbeaver配置,可以关掉。 dbeaver 窗口-首选项-编辑器-数据编辑器 ,把数据集获取大小改为0
所以为什么大家经常测性能的时候,明明程序里面查询很慢,在dbeaver里面却很快,原因就是dbeaver可能偷偷给你加了limit 200。 这个在你测试性能的时候关掉,平时还是加上200的配置吧 5、用mysql自带性能分析可以知道dbeaver默认加了limit 200 set profiling =1; select * from users where user_name =9000; show profiles; 二、尽量不做的事情1.尽量不在where条件用!= 或 <> 2.尽量不用 is null 和 is not null 3.尽量不用or 4.尽量不用like,如果一定要用就用右模糊 user_name like'xx%' 可以用explain验证一下: 在字段已经建立索引的情况下: 'xx%' 走的是range执行计划,前面说过range也是优化目标。 '%xx' 走ALL全表扫描 '%xx%' 走ALL全表扫描如果不是索引字段,那不管什么方式都是ALL全表扫描。 如果要用全模糊,那可以用全文索引解决like慢问题 某个段接like,那么这个字段是不走索引的,所以like就特别慢 ,要700ms
全文索引可以解决这个问题 -- 全文索引create fulltext index idx_users_remark on users(remark); 全文索引查询方式:只要1ms select * from users where Match (remark) Against('备注_100111*' in boolean mode);
5.尽量不用 in not in 6.尽量不要在=左边计算,或函数,如 where to_char(name)='xx' 7.不要用字符串作为主键 8.不要用select * select * 问题: 增加很多不必要的消耗,比如CPU、IO、内存、网络带宽; 增加了使用覆盖索引的可能性; 增加了回表的可能性; 当表结构发生变化时,前端也需要更改; 查询效率低; select * from users;--用时 2.1s
select user_id from users;--用时 453ms
9. 不要用group by having 来过滤,而是先在where 条件过滤后再group by. 10.尽量使得表连接不要超过5个 11.索引不是越多越好,会降低插入更新的速度,控制在5个以内 12.尽量避免使用游标 因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。 13.索引不适合建在有大量重复数据的字段上,比如性别,排序字段应创建索引 14.尽量不要存储图片、文件等大数据。 15.单表数据最好不要超过500w,超过2000w速度明显变慢。 16.in 内数据尽量不要太多,如果是连续的就用between代替。 17.不要在varchar字段上用数字查询,否则会导致索引失效。 比如 user_name =1234 要改成 user_name='1234' 18.复合索引(a,b,c),不要单独用b、c、或者bc进行查询。 复合索引最左原则:a 、ab、abc、ac 都是能用上索引的。 (a,b,c) 为复合索引 ,那么它满足最左原则。什么意思?where a=xx 走索引,其他情况呢 a 走索引 a,b 走索引 , 顺序可以变 ba 也走,mysql会优化位置 a,c 走索引 a,b,c 走索引 b 不走索引 ,为什么这么说,它走的是index,和全表扫描ALL几乎没区别,慢的要死 c 不走索引 , 为什么这么说,它走的是index,和全表扫描ALL几乎没区别,慢的要死 bc 不走索引 就说,必须从最左边开始都要有。 19.主键是自带唯一索引的,因此不需要再在主键上建索引。 三、尽量要做的事情1.复合索引应该要第一个作为条件,否则不生效。 2.能用between 就不要用in 3.exists 代替in 4.数字型字段尽量用number别用varchar 5.查询条件尽量使用上索引 6.varchar代替char varchar 可变,存多少占多少空间;char如果存的不够会补空格。 7.left join 左边放小表(数据量少的表) 8. 尽量使用limit 可以提高查询速度,避免全表扫描。 9.批量插入提高性能。 10.查询使用最频繁的列放在联合索引的最左侧。 INSERT INTO users (user_id,user_name) VALUES(1,'aaa'),(2,'bbb'); 11.财务、银行相关的金额字段必须使用decimal类型 非精准浮点:float,double 精准浮点:decimal Decimal类型为精准浮点数,在计算时不会丢失精度; 占用空间由定义的宽度决定,每4个字节可以存储9位数字,并且小数点要占用一个字节; 可用于存储比bigint更大的整型数据; 12.建议把BLOB或是TEXT列分离到单独的扩展表中 Mysql内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行。而且对于这种数据,Mysql还是要进行二次查询,会使sql性能变得很差,但是不是说一定不能使用这样的数据类型。 如果一定要使用,建议把BLOB或是TEXT列分离到单独的扩展表中,查询时一定不要使用select * 而只需要取出必要的列,不需要TEXT列的数据时不要对该列进行查询。 该文章在 2024/1/22 8:54:26 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886