一、插入数据优化
普通插入:
在平时我们执行insert语句的时候,可能都是一条一条数据插入进去的,就像下面这样。INSERT INTO `department` VALUES(1, '研发部(RD)', '2层'),
INSERT INTO `department` VALUES(2, '人事部(RD)', '1层'),
INSERT INTO `department` VALUES(3, '后勤部(RD)', '4层'),
INSERT INTO `department` VALUES(3, '财务部(RD)', '4层'),
现在我们考虑以下三个方面对insert操作进行优化。
1、采用批量插入(一次插入的数据不建议超过1000条),
执行批量插入,一次性插入的数据不建议超过1000条,如果要插入上万条数据的话,可以将其分割为多条insert语句进行插入。
INSERT INTO `department` (`id`, `deptName`, `address`)
VALUES
(1, '研发部(RD)', '2层'),
(2, '人事部(HR)', '3层'),
(3, '市场部(MK)', '4层'),
(4, '后勤部(MIS)', '5层'),
(5, '财务部(FD)', '6层');
2、手动提交事务
因为一条一条insert插入的时候,如果是自动提交事务,我们的MySQL会频繁的开启、执行事务;
所以我们可以考虑在在大段insert单条插入语句执行的时候,用手动提交事务的方式来执行。
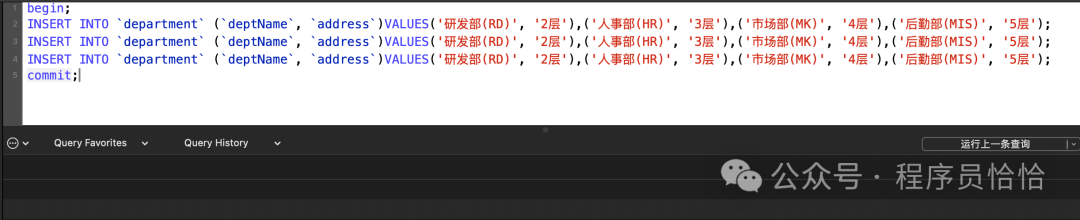
begin;
INSERT INTO `department` (`deptName`, `address`)VALUES('研发部(RD)', '2层'),('人事部(HR)', '3层'),('市场部(MK)', '4层'),('后勤部(MIS)', '5层');
INSERT INTO `department` (`deptName`, `address`)VALUES('研发部(RD)', '2层'),('人事部(HR)', '3层'),('市场部(MK)', '4层'),('后勤部(MIS)', '5层');
INSERT INTO `department` (`deptName`, `address`)VALUES('研发部(RD)', '2层'),('人事部(HR)', '3层'),('市场部(MK)', '4层'),('后勤部(MIS)', '5层');
commit;
3、大批量插入
如果一次性需要插入大批量数据,使用insert语句插入性能较低,此时可以使用MySQL数据库提供的load指令插入。
-- 1、首先,检查一个全局系统变量 'local_infile' 的状态, 如果得到如下显示 Value=OFF,则说明这是不可用的
show global variables like 'local_infile';
-- 2、修改local_infile值为on,开启local_infile
set global local_infile=1;
-- 3、加载数据
/*
脚本文件介绍 :
每一列数据用","分割",
每一行数据用 \n'回车分割
*/
load data local infile 'D:\\sql_data\\sql1.log' into table tb_user fields terminated by ',' lines terminated by '\n';
经过测试,导入100万行数据,仅仅耗时16.84s
注意事项:使用load的时候要按主键顺序插入,主键顺序插入的性能要高于乱序插入的性能。
二、主键优化
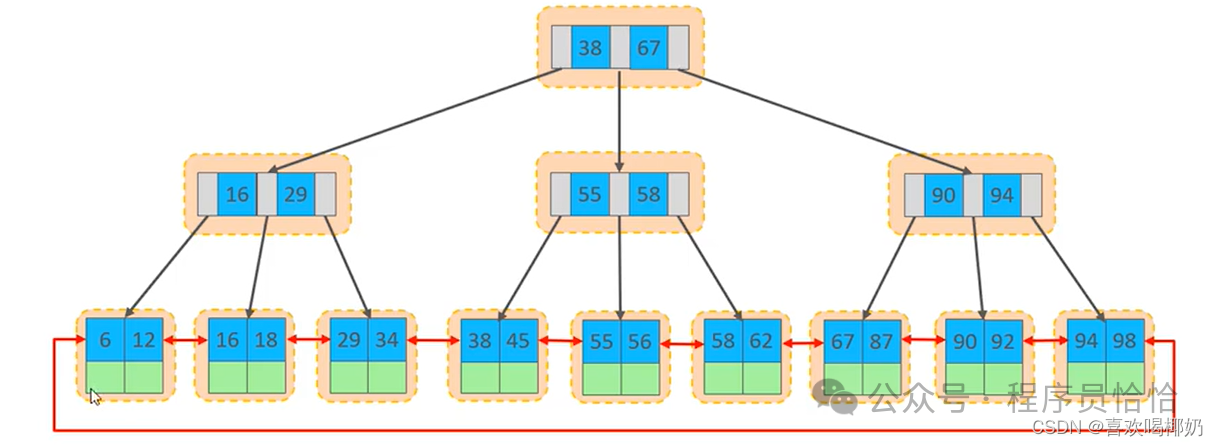
在InnoDB存储引擎中,表数据都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表。我们的InnoDB存储引擎的聚集索引结果中,B+Tree的叶子结点下存储的是row,行数据,并且是根据主键顺序存放。所有的数据都会出现在叶子结点,而非叶子结点仅仅起到了索引的作用。
主键设计原则:
1、满足业务需求的情况下,尽量降低主键的长度
2、插入数据时,尽量选择顺序插入,选择使用AUTO_INCREMENT自增主键
3、尽量不要使用UUID做主键或者是其他自然主键,如身份证号
4、业务操作时,避免对主键的修改
三、order by优化
我们先了解两个概念,前面我们在Explatin详解文章中提到过:SQL性能分析工具Explain详解
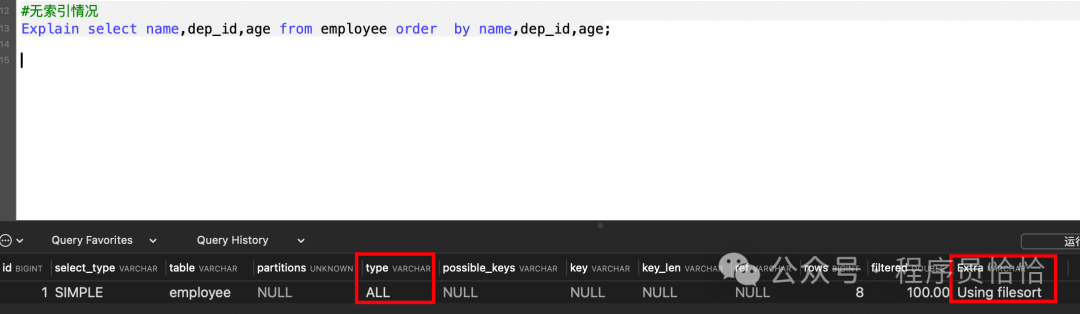
Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区 sort buffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序。
Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高
我们对order by的优化就是尽可能优化为Using index。
新建表:employee
CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`dep_id` int(11) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
`salary` decimal(10,2) DEFAULT NULL,
`cus_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name_dep_id_age` (`name`,`dep_id`,`age`)
) ENGINE=InnoDB AUTO_INCREMENT=109 DEFAULT CHARSET=utf8;
不使用索引情况:
新建联合索引:name,dep_id,age
#创建联合索引
CREATE INDEX idx_name_dep_id_age ON employee (name, dep_id, age);
#查询当前索引
show INDEX from employee
#删除索引
DROP INDEX idx_name_dep_id_age ON employee;
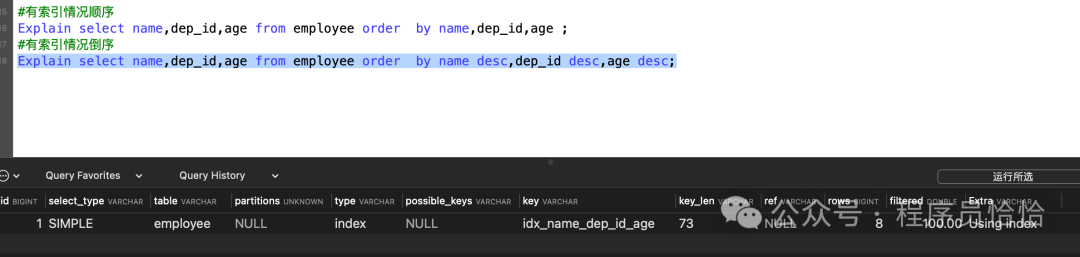
如果order by字段全部使用升序排序或者降序排序,则都会走索引.
#有索引情况顺序
Explain select name,dep_id,age from employee order by name,dep_id,age ;
#有索引情况倒序
Explain select name,dep_id,age from employee order by name desc,dep_id desc,age desc;
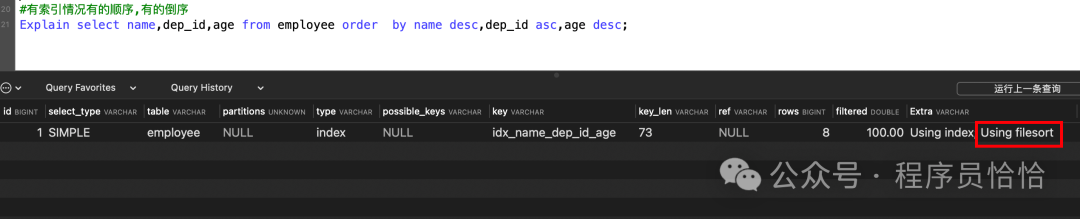
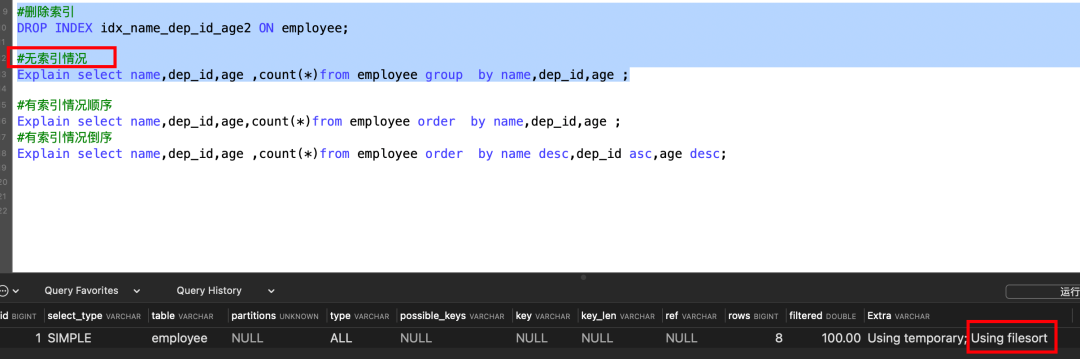
但是如果一个字段升序排序,另一个字段降序排序,则不会走索引,explain的extra信息显示的是Using index, Using filesort.
#有索引情况有的顺序,有的倒序
Explain select name,dep_id,age from employee order by name desc,dep_id asc,age desc;
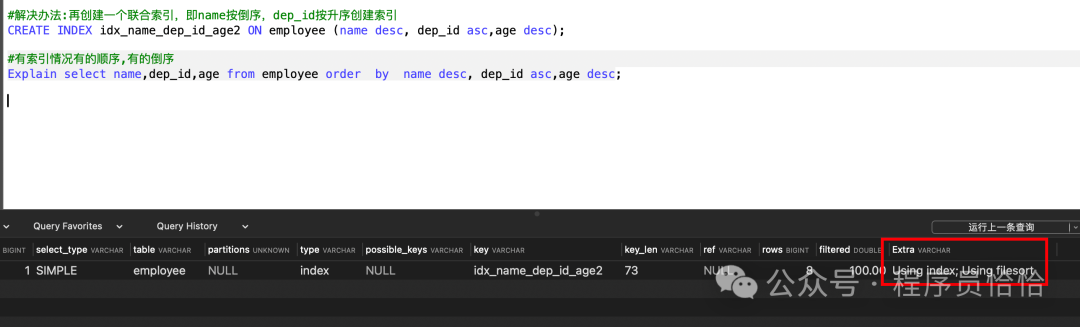
如果要优化掉Using filesort,此时我们可以再创建一个联合索引,即name按倒序,dep_id按升序创建索引,就可以解决。
注意的是虽然我已经创建了覆盖这些列的联合索引 idx_name_dep_id_age2,但 MySQL 优化器仍然可能会决定使用文件排序(filesort)来执行这个顺序的排序操作。
在内存中无法容纳整个结果集时,MySQL 将结果集存储在临时文件中并对其进行排序。这并不一定意味着性能问题,但是可能会影响查询的执行时间,尤其是当处理大量数据时。
- 根据排序字段建立合适的索引,多字段排序时,也遵循最左前缀法则
- 多字段排序,一个升序一个降序,此时需要注意联合索引在创建时的规则(ASC/DESC)
- 如果不可避免出现filesort,大数据量排序时,可以适当增大排序缓冲区大小 sort_buffer_size(默认256k)
四、group by优化
先删除全部的索引(保留主键id)
#删除索引
DROP INDEX idx_name_dep_id_age2 ON employee;
#无索引情况
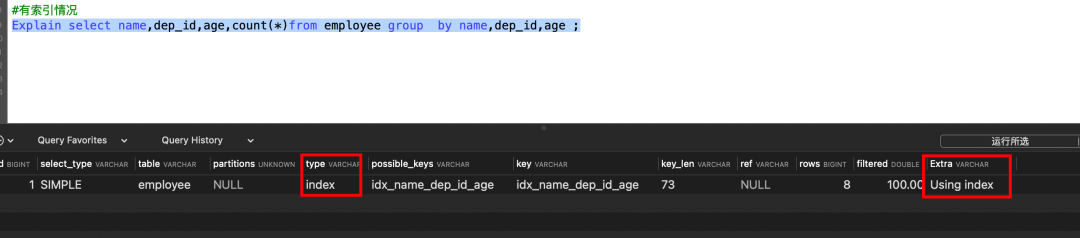
Explain select name,dep_id,age ,count(*)from employee group by name,dep_id,age ;
无索引情况下,分组,出现filesort,type为All出现了全表扫描。
新建联合索引,name,dep_id,age再观察。
#创建联合索引
CREATE INDEX idx_name_dep_id_age ON employee (name, dep_id, age);
#有索引情况
Explain select name,dep_id,age,count(*)from employee group by name,dep_id,age ;
可见用到了索引
总结:
如索引为idx_user_pro_age_stat,则句式可以是select ... where profession order by age,这样也符合最左前缀法则
五、limit优化
语法复习:
#0表示起始位置,10表示每一页展示的数据。
select * from student_info limit 0,10;
这条查询执行的速度非常快,但是如果我们将起始位置设置为100000呢?
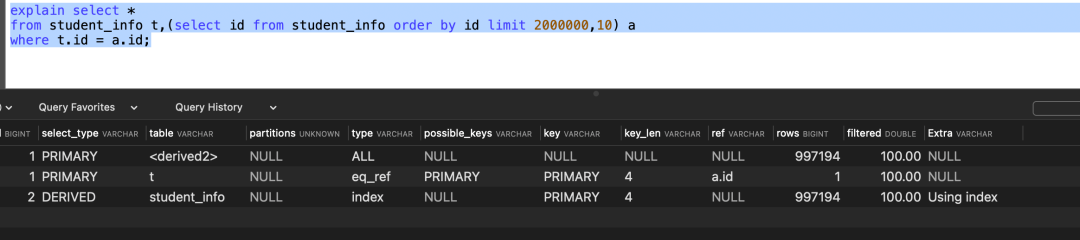
limit分页查询在大数据量的时候,查询效率同样会非常的慢,例如一个常见又非常头疼的问题就是limit 2000000,10 此时需要MySQL排序前200010条记录,仅仅返回200000-2000010的记录,其他记录丢弃,查询排序的代价非常大。
优化方案:一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化explain select *
from student_info t,(select id from student_info order by id limit 2000000,10) a
where t.id = a.id;
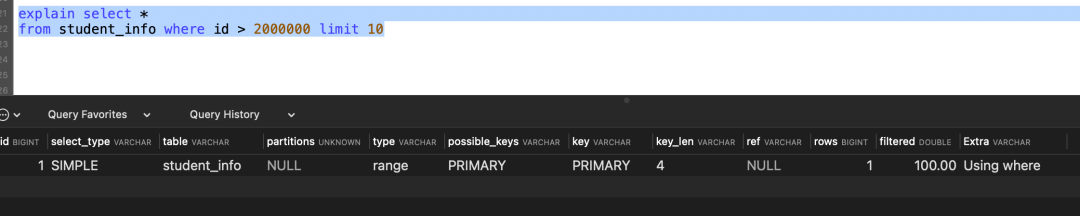
explain select *
from student_info where id > 2000000 limit 10
六、COUNT优化
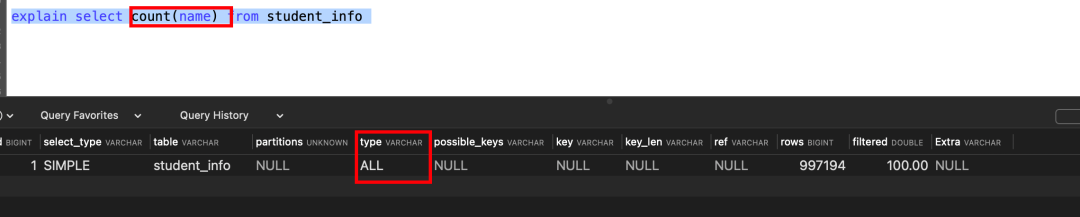
count是一个聚合函数,用于求取符合条件的总数据量。
MyISAM引擎把一个表的总行数存在了磁盘上,因此执行count(*)的时候会直接返回这个数,效率很高。
InnoDB引擎就比较麻烦,它执行count(*)的时候,需要把数据一行一行地从引擎里面读出来,然后累计计数。
count的几种用法:
count()是一个聚合函数,对于返回的结果集,一行行地判断,如果count函数的参数不是NULL,累计值就加1,否则不加,最后返回累计值。
用法:count(*)、count(主键)、count(字段)、count(1)、count(0).
count(主键):InnoDB会遍历整张表,把每一行的主键id值都取出来,返回给服务层。服务层拿到主键后,直接按行进行累加(主键不可能为null)。
count(字段):没有not null约束的话,InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,服务层判断是否为null,不为null,计数累加;有not null约束的话,InnoDB引擎会遍历整张表把每一行的字段值都取出来,返回给服务层,直接按行进行累加。
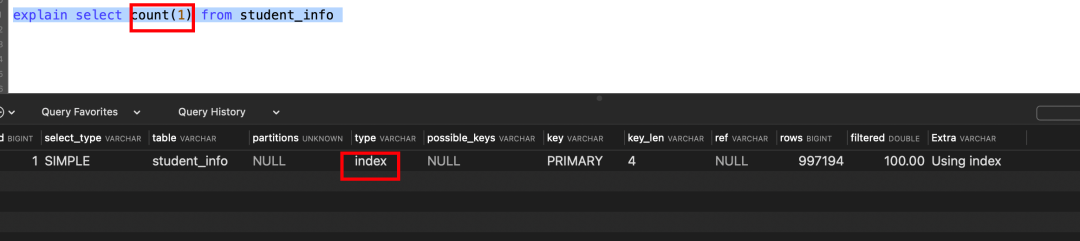
count(1):InnoDB引擎遍历整张表,但不取值。服务层对于返回的每一行,放一个数字“1”进去,直接按行进行累加。
count(*):InnoDB引擎并不会把全部字段取出来,而是专门做了优化,不取值,服务层直接按行进行累加。
按照效率排序:count(字段)<count(主键)<count(1)<count(*)
count(*):
count(1):
七、UPDATE优化
InnoDB 的行锁是针对索引加的锁,不是针对记录加的锁,并且该索引不能失效,否则会从行锁升级为表锁。
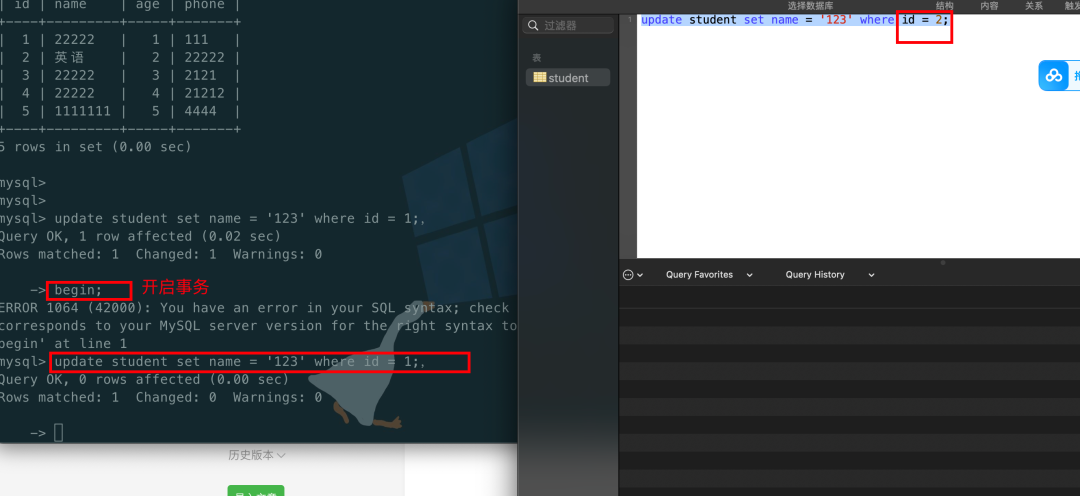
测试1:
开启两个会话:更新student表的数据,会话1更新id为2的数据,会话2更新id为2的数据
会话1:
update student set name = '123' where id = 1;
由于id有主键索引,所以只会锁id = 1这一行;
会话2: id=2,当然会立马执行结束,不用等待会话1提交事务
update student set name = '123' where id = 2;
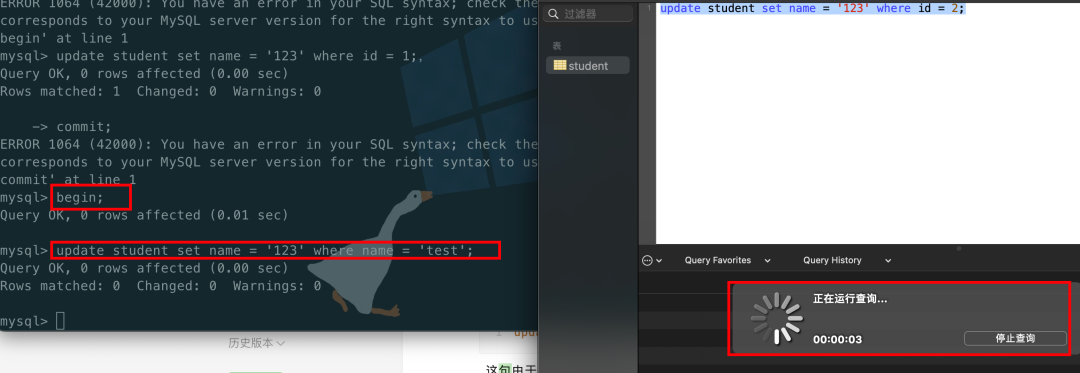
开启两个会话:更新student表的数据,会话1更新name(name字段无索引)为2的数据,会话2更新id为2的数据update student set name = '123' where name = 'test';
由于name没有索引,所以会把整张表都锁住,导致会话2等待会话1提交事务。
记住一点,根据索引字段去更新数据即可!(因为索引字段相当于上的行锁,非索引字段上的表锁)。
该文章在 2024/4/28 22:05:33 编辑过






 400 186 1886
400 186 1886