OCR识别颠覆者!Zerox:一键将PDF/图片转Markdown,复杂表格、手写体精准还原
|
admin 2025年2月26日 20:59
本文热度 1743
2025年2月26日 20:59
本文热度 1743
|
在处理文档转换时,尤其是将 PDF 转换为可编辑的 Markdown 格式,我们常常会遇到各种难题,比如复杂的布局、表格、图表等元素难以准确识别和转换。
今天给大家介绍一个强大的开源项目——Zerox,它利用视觉模型技术,能够轻松解决这些问题,让你的文档转换工作变得高效而准确。
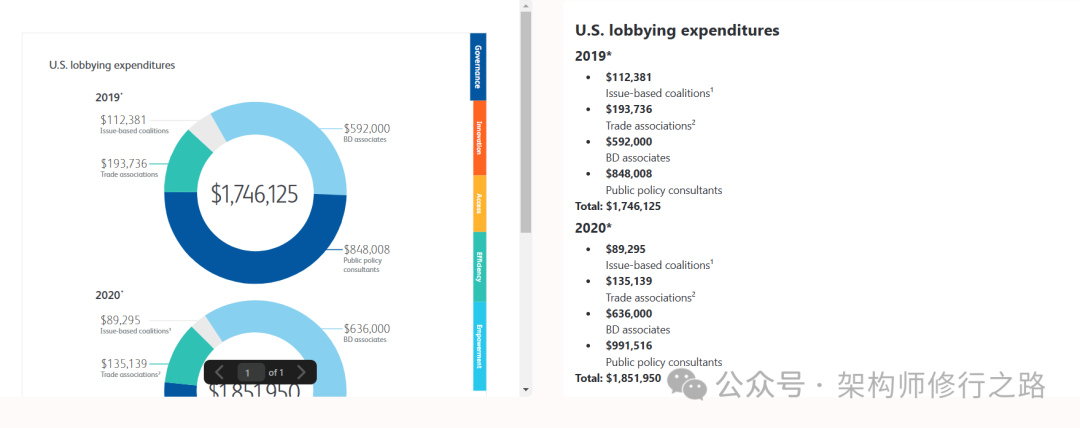
为什么Zerox值得关注?
1. 零样本OCR识别,开箱即用
传统OCR工具需要大量样本训练才能精准识别文字,而Zerox基于GPT-4o-mini模型,无需任何预训练即可处理复杂布局文档,包括表格、图表甚至手写体,准确率远超同类工具。
2. 输出Markdown格式,完美保留结构
无论是PDF、DOCX还是扫描图片,Zerox都能将内容转换为结构化Markdown,自动生成标题、列表、表格等元素。例如,发票中的金额表格能直接转为Markdown表格,方便二次编辑。
3. 手写体识别“杀手锏”
许多OCR工具对打印体效果尚可,但对手写体束手无策。Zerox通过多模型兼容技术,对手写笔记、签名等内容的识别准确率高达90%以上,堪称“打工人救星”。
4. 支持API集成,企业级效率工具
开发者可通过Node或Python SDK快速集成Zerox,实现批量文档处理自动化。适用于法律合同解析、学术论文整理等场景,节省80%人工整理时间。

3步极速上手Zerox
第一步:安装依赖
npm install zerox # Node版本
# 或
pip install zerox # Python版本
第二步:调用API识别文件
以Node为例,读取PDF并输出Markdown:
import { zerox } from "zerox";
const result = await zerox({
filePath: "invoice.pdf", // 支持本地文件或URL
openaiAPIKey: "YOUR_API_KEY", // 需自备OpenAI API Key
});
console.log(result.pages[0].content); // 输出Markdown内容
第三步:查看结果
生成的Markdown会自动包含表格、标题层级和文本样式,例如:
Zerox vs 其他OCR工具:差异在哪?
- • 格式兼容性:支持20+文件格式(包括冷门的WPS、ODT等),而多数工具仅限PDF/图片。
- • 并发处理:可同时处理多页文档,速度比传统工具快3倍。
- • 开源免费:代码完全公开,企业可二次开发,避免商业OCR的高额授权费。
项目地址:https://github.com/getomni-ai/zerox
阅读原文:原文链接
该文章在 2025/2/27 10:42:42 编辑过






 400 186 1886
400 186 1886

